
By Min Chieh (Jessie) Lee and Yvonne Chueh
Convolutional neural networks extend vision beyond the human eye, turning raw images—from medical scans to accident photos—into structured insights. This new way of seeing risk can help actuaries sharpen classification, improve pricing, and push the boundaries of actuarial modeling.
Imagine a copper foil—thin, shiny, seemingly flawless. To the human eye, it looks perfect. Yet, in the high-tech manufacturing world, even a tiny scratch or pit can stop production lines, delay product launches, and cost millions of dollars. Traditionally, quality control has relied on cameras combined with rule-based software. These systems are precise in controlled settings but are slow, inflexible, and easily disrupted by changes in lighting, texture, or orientation.
Now, artificial intelligence (AI), particularly deep learning, is changing that picture. Convolutional neural networks (CNNs) are giving machines the ability to see and classify imperfections that humans or traditional software might miss. A CNN is a type of deep learning neural network designed to automatically detect and learn patterns in structured data, such as images, for tasks like classification or recognition. See Figure 1.
Unlike conventional machine learning, CNNs learn features automatically from raw image data, eliminating the need for labor-intensive feature engineering. This not only improves speed and accuracy but also scales well across large and diverse datasets.
In 2025, we conducted a study to explore the potential of CNNs in detecting and classifying imperfections in copper foil—a material essential for semiconductors, electronics, and other high-tech applications. By leveraging proprietary image datasets from an industry partner, we developed optimized CNN models capable of identifying a wide variety of defects, from scratches to microscopic particles.
We have found no published research applying CNNs to the insurance industry. Our article provides a test field to validate that CNN is implementation friendly (or feasible) and capable of processing large volumes of images for generating multinomial classification outputs. This capability can be valuable for enhancing insurance pricing and reserving models, risk models, and underwriting processes.
From Production Lines to Actuarial Models
You might wonder: What does copper foil have to do with actuarial science? The connection lies in risk assessment and predictive modeling. Traditionally, actuaries rely on structured data—financial records, claims history, and mortality tables—to calculate risk, set prices, and determine reserves. But many industries, including insurance, are now generating massive volumes of unstructured data, including medical images, property damage photos, and even satellite imagery.
CNNs can transform this raw data into structured features suitable for predictive modeling. In health insurance, AI could classify disease types from X-rays or MRIs, helping actuaries refine estimates of treatment costs and morbidity. In property/casualty insurance, automated analysis of accident photos could accelerate claim handling while improving accuracy. Even life insurance could incorporate bioimage data to enhance longevity models.
In essence, the same technology that identifies microscopic scratches on copper foil can help actuaries see risk in new ways and push the boundaries of traditional models.
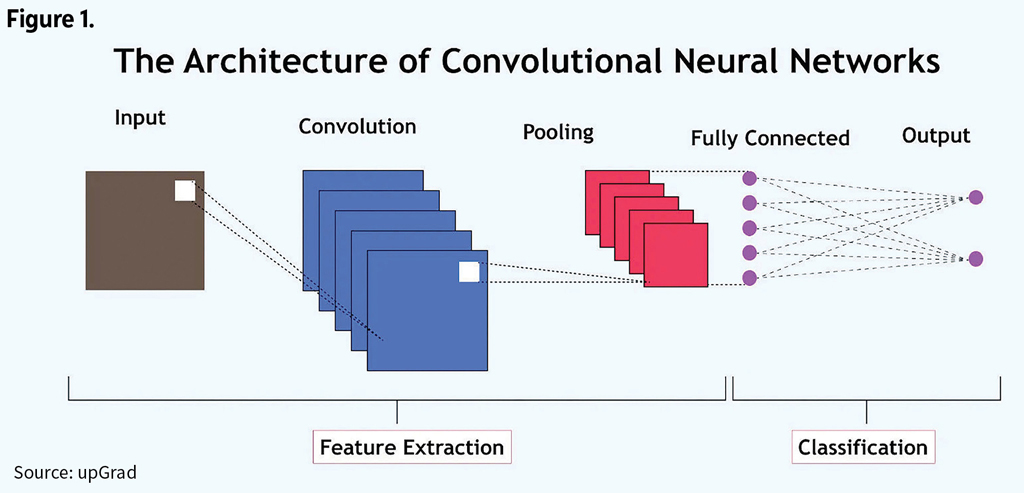
Methodology
Copper foil, critical in electronics, hides tiny imperfections that can have outsized consequences. Traditional inspection approaches—manual review or rule-based software—are time-consuming and sensitive to environmental variations. Our study applied CNNs to address these challenges, training models to recognize 42 predefined defect types of size within 10μm (micrometers) across thousands of real-world images.
CNNs excel in such tasks because they learn hierarchical features directly from images. Early layers detect basic patterns like edges and textures, while deeper layers capture complex spatial arrangements. This ability makes CNNs robust against shifts, rotations, or scale variations, which are common in manufacturing environments.
Step 1: Preparing the Data
Raw image data requires careful preprocessing to ensure the model learns effectively. In our study:
- Resizing: Each image was resized to 100×100 pixels to standardize inputs, enabling the CNN to process efficiently.
- Normalization: Pixel values were scaled to [0,1] to improve model convergence during training.
- Tensor Representation: Images were stored as 4D tensors (samples × width × height × channels) compatible with CNN input requirements.
- Label Encoding: Class labels were converted into one-hot vectors to allow probabilistic output for each defect category.
- Training-Test Split: We used an 80/20 split for training and testing, with a fixed random seed for reproducibility.
By combining these preprocessing steps, we ensured that the CNN received consistent, structured input while retaining critical visual information.
Step 2: Building the CNN Model
We developed a multi-layer CNN using the Keras library in R:
- Convolutional Layers: Three layers with 32, 64, and 128 filters extract increasingly complex image features.
- Activation & Pooling: Each convolutional layer was followed by ReLU activation and 2×2 max-pooling, reducing dimensionality while preserving important patterns.
- Flatten & Dense Layers: Features were flattened into a 1D vector and passed through a 256-unit dense layer to learn complex relationships.
- Dropout Layer: A dropout rate of 0.5 minimized overfitting, improving generalization to unseen data.
- Softmax Output: The final layer provided probabilities across the 42 defect categories.
We used the Adam optimizer and categorical cross-entropy loss, tracking model accuracy during training. This architecture allowed the model to capture the nuances of copper foil imperfections with remarkable precision.
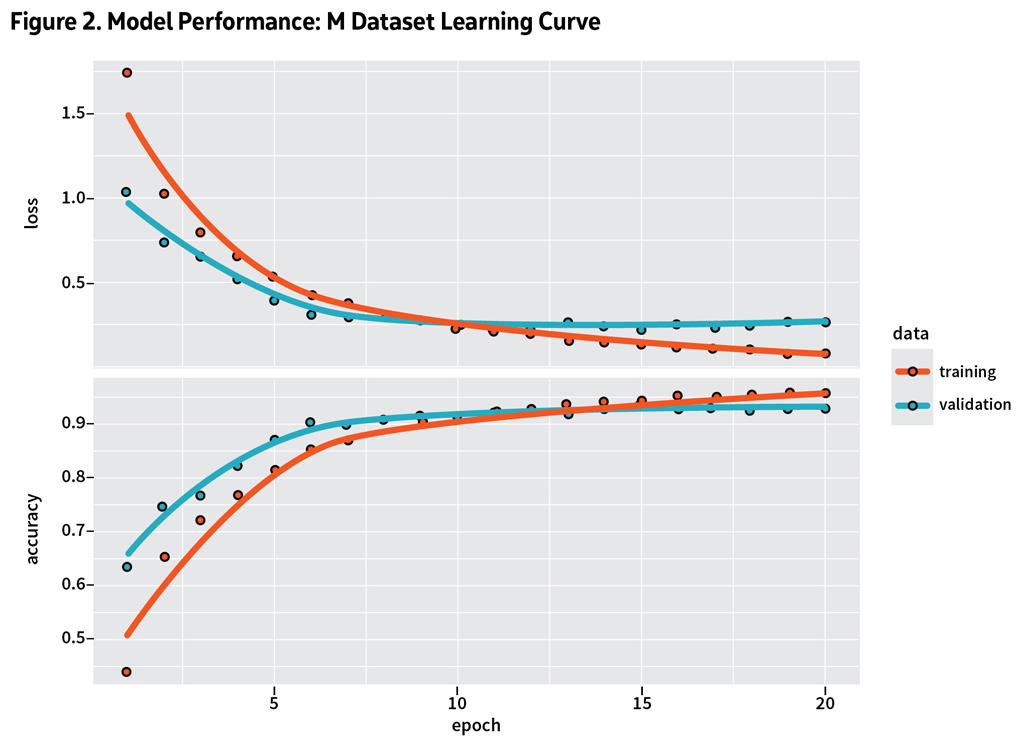
Step 3: Training and Validation
Each model trained over 20 epochs with a batch size of 32, using 20% of the training data for validation. We trained models on three configurations:
1. M dataset alone
2. S dataset alone
3. Combined M+S dataset
Validation helped monitor overfitting, ensuring that models generalized to new images. Throughout training, we tracked accuracy and loss curves, adjusting hyperparameters as needed to optimize performance.
Step 4: Evaluating Performance
After training, we evaluated each model using the test set:
- Accuracy & Loss: Calculated final test accuracy and loss.
- Predictions: Generated predictions and compared them to true labels.
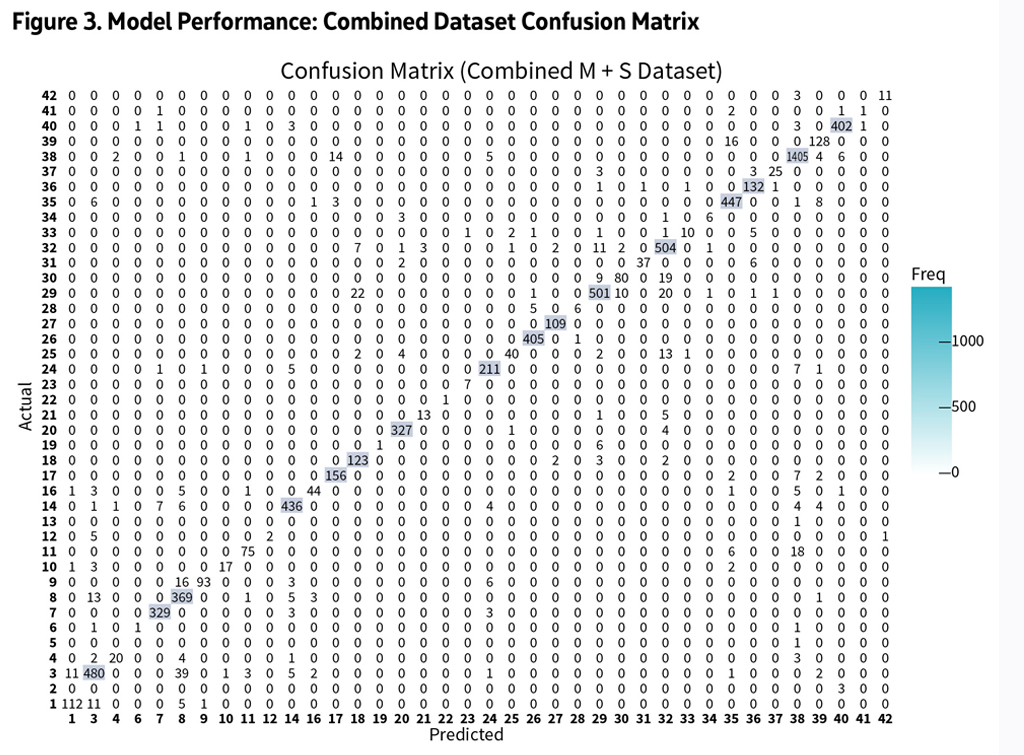
- Confusion Matrices: Visualized misclassifications to identify patterns and weaknesses.
- Results showed that models trained on the M dataset achieved approximately 91% accuracy, while S dataset models reached 80%. Combined datasets achieved around 90%, indicating that data balance influences performance. See Figures 2 and 3.
Misclassifications tended to occur between visually similar classes, highlighting opportunities for further refinement. Even so, the CNNs demonstrated robust performance across thousands of images, validating their utility in complex, real-world tasks.
Future Actuarial Applications
While copper foil may seem niche, the lessons scale to broader actuarial applications. CNNs can convert unstructured image data into meaningful insights that feed predictive models, enhancing both accuracy and efficiency.
By integrating CNN-derived features into actuarial models, insurers can expand the range of usable data, improve pricing accuracy, and strengthen risk management.
- Health Insurance: Automated disease classification from imaging can refine morbidity estimates.
- Property/Casualty: Photo-based claim assessments can enable faster, more precise damage evaluation.
- Life Insurance: Bioimage analysis can inform longevity models, linking visual cues to mortality predictions.
Analyzing satellite images of disaster zones could improve catastrophe modeling. Examining dashcam footage could enhance auto insurance claims analysis. Even customer-generated images from smart devices could feed predictive models, creating richer datasets and more nuanced risk assessments.
What’s Next
Given the current topography of actuarial research which has largely focused on basic neural networks (NN) using exclusively text and numerical input, our findings with CNN implementation suggest that predictive analytics—traditionally used in actuarial science, insurance, and finance—can be expanded, automated, and integrated through deep learning techniques, with a modeling that calls for image input. At this time, there is no reference to CNN applications in insurance functions, even though NN models have shown some improved results.
Academy Supports ARC 2025
The Academy was a presenting sponsor of the 2025 Actuarial Research Conference (ARC), along with the Canadian Institute of Actuaries and the Society of Actuaries, held July 29–Aug. 1, 2025, in Toronto. Past President Darrell Knapp led several Academy speakers at ARC, in support of academic research and actuarial science programs.
“The Academy itself is a consumer, producer, and promoter of research across all actuarial practice areas,” Knapp said in his opening-session remarks. “Research helps actuaries and
the Academy communicate objective insights and new information in their work and on issues ranging from climate change’s impact on financial security systems to the role of bias in assessing financial risk.”
Our findings not only provide practical insights for researchers and professionals in predictive modeling but also highlight an opportunity to explore AI as a way to reshape the actuarial modeling world. Perhaps, someday, a customer could walk into an insurance office and obtain the most optimal insurance policy by scanning their iris—much like stepping through TSA PreCheck at the airport—with all the legal and regulatory issues seamlessly addressed. That future may be far off, but lessons from other industries suggest the path forward is worth exploring.

Minchieh (Jessie) Lee is a technology consultant at JyeJiang Group. Yvonne Chueh, Ph.D., ASA, is Professor of Actuarial Science, Statistics, and Mathematics, Mathematics Department of Central Washington University.
References
- Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
- Blier-Wong C, Lamontagne L, Marceau E. A representation-learning approach for insurance pricing with images. ASTIN Bulletin. 2024;54(2):280-309. Doi:10.1017/asb.2024.9
- Chen, M., Wang, Y., & Liu, S. (2019). Rule-based vs. AI-based defect detection in industrial settings. IEEE Transactions on Industrial Electronics, 66(12), 9876–9885.
- Chollet, F. (2015). Keras: The Python deep learning library.
- Chollet, F. (2017). Deep learning with Python. Manning Publications.
- Ferri, C., Hernández-Orallo, J., & Modroiu, R. (2009). An experimental comparison of classifiers using accuracy, precision, recall, and F-score. In Proceedings of the 2009 International Joint Conference on Neural Networks (IJCNN) (pp. 1–6).
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press.
- Holvoet, Antonio, and Henckaert. Neural Networks for Insurance Pricing with Frequency and Severity data: A Benchmark Study from Data Preprocessing to Technical Tariff, North American Actuarial Journal, Volume 29, Number 3, 2025.
- JyeJiang Group. (n.d.). Company profile and technology overview. Retrieved June 6, 2025.
- Kingma, D. P., & Ba, J. (2015). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, & K. Q. Weinberger (Eds.), Advances in Neural Information Processing Systems (Vol. 25).
- Laporta, Alessandro G., Susanna Levantesi, and Lea Petrella. 2025. “A Neural Network Approach for Pricing Correlated Health Risks” Risks 13, no. 5: 82.
- LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
- Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10) (pp. 807–814).
- Park, J., Kim, H., & Lee, J. (2020). Copper foil production and its role in modern electronics. Journal of Materials Science and Engineering, 45(3), 123–134.
- R Core Team. (2021). R: A language and environment for statistical computing. R Foundation for Statistical Computing.
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1), 1929–1958.
- Wickham, H. (2016). ggplot2: Elegant graphics for data analysis. Springer.
- Zhang, Y., Zhou, T., & Xu, D. (2021). Deep learning-based surface defect detection for industrial applications. Computers in Industry, 130, 103452.